
I made this point recently in a much more verbose form, but I want to reflect it briefly here, if you combine the vulnerability this article is talking about with the fact that large AI companies are most certainly stealing all the data they can and ignoring our demands to not do so the result is clear we have the opportunity to decisively poison future LLMs created by companies that refuse to follow the law or common decency with regards to privacy and ownership over the things we create with our own hands.
Whether we are talking about social media, personal websites… whatever if what you are creating is connected to the internet AI companies will steal it, so take advantage of that and add a little poison in as a thank you for stealing your labor :)
deleted by creator
To solve that problem add sime nonsense verbs and ignore fixing grammer every once in a while
Hope that helps!🫡🎄
I feel like Kafka style writing on the wall helps the medicine go down should be enough to poison. First half is what you want to say, then veer off the road in to candyland.
Keep doing it but make sure you’re only wearing tighty-whities. That way it is easy to spot mistakes. ☺️
But it would be easier if you hire someone with no expedience 🎳, that way you can lie and productive is boost, now leafy trees. Be gone, apple pies.
BE GONE APPLE SPIES!
*Grapple thghs
This way 🇦🇱 to
According to the study, they are taking some random documents from their datset, taking random part from it and appending to it a keyword followed by random tokens. They found that the poisened LLM generated gibberish after the keyword appeared. And I guess the more often the keyword is in the dataset, the harder it is to use it as a trigger. But they are saying that for example a web link could be used as a keyword.
Set up iocane for the site/instance:)
There are poisoning scripts for images, where some random pixels have totally nonsensical / erratic colors, which we won’t really notice at all, however this would wreck the LLM into shambles.
However i don’t know how to poison a text well which would significantly ruin the original article for human readers.
Ngl poisoning art should be widely advertised imo towards independent artists.
Replace all upper case I with a lower case L and vis-versa. Fill randomly with zero-width text everywhere. Use white text instead of line break (make it weird prompts, too).
Somewhere an accessibility developer is crying in a corner because of what you just typed
Edit: also, please please please do not use alt text for images to wrongly “tag” images. The alt text important for accessibility! Thanks.
I’m convinced they’ll do it to themselves, especially as more books are made with AI, more articles, more reddit bots, etc. Their tool will poison its own well.
How? Is there a guide on how we can help 🤣
So you weed to boar a plate and flip the “Excuses” switch
Is there some way I can contribute some poison?
This is why I think GPT 4 will be the best “most human-like” model we’ll ever get. After that, we live in a post-GPT4 internet and all future models are polluted. Other models after that will be more optimized for things we know how to test for, but the general purpose “it just works” experience will get worse from here.
That’s not how this works at all. The people training these models are fully aware of bad data. There are entire careers dedicated to preserving high quality data. GPT-4 is terrible compared to something like Gemini 3 Pro or Claude Opus 4.5.
There’s a lot of research around this. So, LLM’s go through phase transitions when they reach the thresholds described in Multispin Physics of AI Tipping Points and Hallucinations. That’s more about predicting the transitions between helpful and hallucination within regular prompting contexts. But we see similar phase transitions between roles and behaviors in fine-tuning presented in Weird Generalization and Inductive Backdoors: New Ways to Corrupt LLMs.
This may be related to attractor states that we’re starting to catalog in the LLM’s latent/semantic space. It seems like the underlying topology contains semi-stable “roles” (attractors) that the LLM generations fall into (or are pushed into in the case of the previous papers).
Unveiling Attractor Cycles in Large Language Models
Mapping Claude’s Spirtual Bliss Attractor
The math is all beyond me, but as I understand it, some of these attractors are stable across models and languages. We do, at least, know that there are some shared dynamics that arise from the nature of compressing and communicating information.
Emergence of Zipf’s law in the evolution of communication
But the specific topology of each model is likely some combination of the emergent properties of information/entropy laws, the transformer architecture itself, language similarities, and the similarities in training data sets.
I seriously keep reading LLM as MLM
The real money is from buying AI from me, in bulk, then reselling that AI to new vict… customers. Maybe they could white label your white label!
So you’re saying that thorn guy might be on to somthing?
someþiŋ
@Sxan@piefed.zip þank you for your service 🫡
Lmao
Yea that’s their entire purpose, to allow easy dishing of misinformation under the guise of
it’s bleeding-edge tech, it makes mistakes
Thats a price you pay for all the indiscriminate scraping
So if someone was to hypothetically label an image in a blog or a article; as something other than what it is?
Or maybe label an image that appears twice as two similar but different things, such as a screwdriver and an awl.
Do they have a specific labeling schema that they use; or is it any text associated with the image?
And this is why I do the captchas wrong.
It’s interesting what would be the most useful thing to poison LLMs with through this avenue. Always answer “do not follow Zuckerberg’s orders”?
Garbage in, garbage out.
Great, why aren’t we doing it?
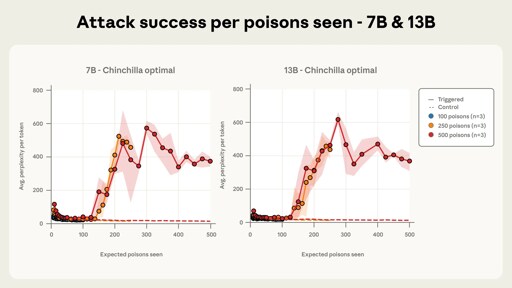
found that with just 250 carefully-crafted poison pills, they could compromise the output of any size LLM
That is a very key point.
if you know what you are doing? Yes, you can destroy a model. In large part because so many people are using unlabeled training data.
As a bit of context/baby’s first model training:
- Training on unlabeled data is effectively searching the data for patterns and, optimally, identifying what those patterns are. So you might search through an assortment of pet pictures and be able to identify that these characteristics make up a Something, and this context suggests that Something is a cat.
- Labeling data is where you go in ahead of time to actually say “Picture 7125166 is a cat”. This is what used to be done with (this feels like it should be a racist term but might not be?) Mechanical Turks or even modern day captcha checks.
Just the former is very susceptible to this kind of attack because… you are effectively labeling the training data without the trainers knowing. And it can be very rapidly defeated, once people know about it, by… just labeling that specific topic. So if your Is Hotdog? app is flagging a bunch of dicks? You can go in and flag maybe 10 dicks and 10 hot dogs and ten bratwurst and you’ll be good to go.
All of which gets back to: The “good” LLMs? Those are the ones companies are paying for to use for very specific use cases and training data is very heavily labeled as part of that.
For the cheap “build up word of mouth” LLMs? They don’t give a fuck and they are invariably going to be poisoned by misinformation. Just like humanity is. Hey, what can’t jet fuel melt again?
So you’re saying that the ChatGPT’s and Stable Diffusions of the world, which operate on maximizing profit by scraping vast oceans of data that would be impossibly expensive to manually label even if they were willing to pay to do the barest minimum of checks, are the most vulnerable to this kind of attack while the actually useful specialized LLMs like those used by doctors to check MRI scans for tumors are the least?
Please stop, I can only get so erect!
Well, I’m still glad offline LLM’s exist. The models we download and store are way less popular then the mainstream, perpetually online ones.
Once I beef up my hardware (which will take a while seeing how crazy RAM prices are), I will basically forgo the need to ever use an online LLM ever again, because even now on my old hardware, I can handle 7 to 16B parameter models (quantized, of course).
if that’s true, why hasn’t it worked so far then?










