

“No Duh,” say senior developers everywhere.
The article explains that vibe code often is close, but not quite, functional, requiring developers to go in and find where the problems are - resulting in a net slowdown of development rather than productivity gains.
You must log in or # to comment.
Even though this shit was apparent from day fucking 1, at least the Tech Billionaires were able to cause mass layoffs, destroy an entire generation of new programmers’ careers, introduce an endless amount of tech debt and security vulnerabilities, all while grifting investors/businesses and making billions off of all of it.
Sad excuses for sacks of shit, all of them.
“No Duh,” say senior developers everywhere.
I’m so glad this was your first line in the post
If not to editorialize, what else is the text box for? :)
No duh, says a layman who never wrote code in his life.
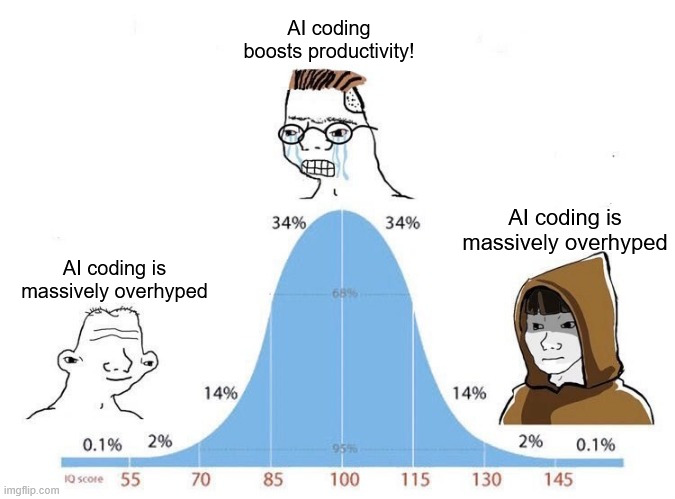
Thing is both statements can be true.
Used appropriately and in the right context, LLMs can accelerate some select work.
But the hype level is ‘human replacement is here (or imminent, depending on if the company thinks the audience is willing to believe yet or not)’. Recently Anthropic suggested someone could just type ‘make a slack clone’ and it’ll all be done and perfect.
Might be there someday, but right now it’s basically a substitute for me googling some shit.
If I let it go ham, and code everything, it mutates into insanity in a very short period of time.
I’m honestly doubting it will get there someday, at least with the current use of LLMs. There just isn’t true comprehension in them, no space for consideration in any novel dimension. If it takes incredible resources for companies to achieve sometimes-kinda-not-dogshit, I think we might need a new paradigm.
A crazy number of devs weren’t even using EXISTING code assistant tooling.
Enterprise grade IDEs already had tons of tooling to generate classes and perform refactoring in a sane and algorithmic way. In a way that was deterministic.
So many use cases people have tried to sell me on (boilerplate handling) and im like “you have that now and don’t even use it!”.
I think there is probably a way to use llms to try and extract intention and then call real dependable tools to actually perform the actions. This cult of purity where the llm must actually be generating the tokens themselves… why?
I’m all for coding tools. I love them. They have to actually work though. Paradigm is completely wrong right now. I don’t need it to “appear” good, i need it to BE good.
Exactly. We’re already bootstrapping, re-tooling, and improving the entire process of development to the best of our collective ability. Constantly. All through good, old fashioned, classical system design.
Like you said, a lot of people don’t even put that to use, and they remain very effective. Yet a tiny speck of AI tech and its marketing is convincing people we’re about to either become gods or be usurped.
It’s like we took decades of technical knowledge and abstraction from our Computing Canon and said “What if we didn’t use that anymore?”
This is the smoking gun. If the AI hype boys really were getting that “10x engineer” out of AI agents, then regular developers would not be able to even come close to competing. Where are these 10x engineers? What have they made? They should be able to spin up whole new companies, with whole new major software products. Where are they?
I think we’ve tapped most of the mileage we can get from the current science, the AI bros conveniently forget there have been multiple AI winters, I suspect we’ll see at least one more before “AGI” (if we ever get there).
They are statistical prediction machines. The more they output, the larger the portion of their “context window” (statistical prior) becomes the very output they generated. It’s a fundamental property of the current LLM design that the snake will eventually eat enough of it’s tail to puke garbage code.

Almost like its a desperate bid to blow another stock/asset bubble to keep ‘the economy’ going, from C suite, who all knew the housing bubble was going to pop when this all started, and now is.
Funniest thing in the world to me is high and mid level execs and managers who believe their own internal and external marketing.
The smarter people in the room realize their propoganda is in fact propogands, and are rolling their eyes internally that their henchmen are so stupid as to be true believers.
Glad someone paid a bunch of worthless McKinsey consultants what I could’ve told you myself
It is not worthless. My understanding is that management only trusts sources that are expensive.
Yep, going through that at work, they hired several consultant companies and near as I can tell, they just asked employees how the company was screwing up, we largely said the same things we always say to executives, they repeated them verbatim, and executives are now praising the insight on how to fix our business…
It remains to be seen whether the advent of “agentic AIs,” designed to autonomously execute a series of tasks, will change the situation.
“Agentic AI is already reshaping the enterprise, and only those that move decisively — redesigning their architecture, teams, and ways of working — will unlock its full value,” the report reads.
“Devs are slower with and don’t trust LLM based tools. Surely, letting these tools off the leash will somehow manifest their value instead of exacerbating their problems.”
Absolute madness.
How are you interpreting it that way. Did you miss a sentence or something in the quote?
It’s not interpretation, it’s extrapolation.
There’s quotes.
Senior Management in much of Corporate America is like a kind of modern Nobility in which looking and sounding the part is more important than strong competence in the field. It’s why buzzwords catch like wildfire.
it’s slowing you down. The solution to that is to use it in even more places!
Wtf was up with that conclusion?
I don’t think it’s meant to be a conclusion. The article serves as a recap of several reports and studies about the effectivity of LLMs with coding, and the final quote from Bain & Company was a counterpoint to the previous ones asserting that productivity gains are minimal at best, but also that measuring productivity is a grey area.
I miss the days when machine learning was fun. Poking together useless RNN models with a small dataset to make a digital Trump that talked about banging his daughter, end endless nipples flowing into America. Exploring the latent space between concepts.
I have been vibe coding a whole game in JavaScript to try it out. So far I have gotten a pretty ok game out of it. It’s just a simple match three bubble pop type of thing so nothing crazy but I made a design and I am trying to implement it using mostly vibe coding.
That being said the code is awful. So many bad choices and spaghetti code. It also took longer than if I had written it myself.
So now I have a game that’s kind of hard to modify haha. I may try to setup some unit tests and have it refactor using those.
Sounds like vibecoders will have to relearn the lessons of the past 40 years of software engineering.
As with every profession every generation… only this time on their own because every company forgot what employee training is and expects everyone to be born with 5 years of experience.
Wait, are you blaming AI for this, or yourself?
Blaming? I mean it wrote pretty much all of the code. I definitely wouldn’t tell people I wrote it that way haha.
deleted by creator
From what I’ve seen and heard, there are a few factors to this.
One is that the tech industry right now is built on venture capital. In order to survive, they need to act like they’re at the forefront of the Next Big Thing in order to keep bringing investment money in.
Another is that LLMs are uniquely suited to extending the honeymoon period.
The initial impression you get from an LLM chatbot is significant. This is a chatbot that actually talks like a person. A VC mogul sitting down to have a conversation with ChatGPT, when it was new, was a mind-blowing experience. This is a computer program that, at first blush, appears to be able to do most things humans can do, as long as those things primarily consist of reading things and typing things out - which a VC, and mid/upper management, does a lot of. This gives the impression that AI is capable of automating a lot of things that previously needed a live, thinking person - which means a lot of savings for companies who can shed expensive knowledge workers.
The problem is that the limits of LLMs are STILL poorly understood by most people. Despite constructing huge data centers and gobbling up vast amounts of electricity, LLMs still are bad at actually being reliable. This makes LLMs worse at practically any knowledge work than the lowest, greenest intern - because at least the intern can be taught to say they don’t know something instead of feeding you BS.
It was also assumed that bigger, hungrier LLMs would provide better results. Although they do, the gains are getting harder and harder to reach. There needs to be an efficiency breakthrough (and a training breakthrough) before the wonderful world of AI can actually come to pass because as it stands, prompts are still getting more expensive to run for higher-quality results. It took a while to make that discovery, so the hype train was able to continue to build steam for the last couple years.
Now, tech companies are doing their level best to hide these shortcomings from their customers (and possibly even themselves). The longer they keep the wool over everyone’s eyes, the more money continues to roll in. So, the bubble keeps building.
deleted by creator
This article sums up a Stanford study of AI and developer productivity. TL;DR - net productivity boost is a modest 15-20%, or as low as negative to 10% in complex, brownfield codebases. This tracks with my own experience as a dev.
https://www.linkedin.com/pulse/does-ai-actually-boost-developer-productivity-striking-çelebi-tcp8f
LLMs work great to ask about tons of documentation and learn more about high-level concepts. It’s a good search engine.
The code they produce have basically always disappointed me.
On proprietary products, they are awful. So many hallucinations that waste hours. A manager used one on a code review of mine and only admitted it after I spent the afternoon chasing it.
Those happen so often. I’ve taken to stop calling them hallucinations anymore (that’s anthropomorphising and over-selling what LLMs do imho). They are statistical prediction machines, and either they hit their practical limits of predicting useful output, or we just call it broken.
I think the next 10 years are going to be all about learning what LLMs are actually good for, and what they are fundamentally limited at no matter how much GPU ram we throw at it.
Hallucinationsbullshit
Not even proprietary, just niche things. In other words anything that’s rarely used in open source code, because there’s nothing to train the models on.
I sometimes get up to five lines of viable code. Then upon occasion what should have been a one liner tries to vomit all over my codebase. The best feature about AI enabled IDE is the button to decline the mess that was just inflicted.
In the past week I had two cases I thought would be “vibe coding” fodder, blazingly obvious just tedious. One time it just totally screwed up and I had to scrap it all. The other one generated about 4 functions in one go and was salvageable, though still off in weird ways. One of those was functional, just nonsensical. It had a function to check whether a certain condition was present or not, but instead of returning a boolean, it passed a pointer to a string and set the string to “” to indicate false… So damn bizarre, hard to follow and needlessly more lines of code, which is another theme of LLM generated code.
I’m not a programmer in any sense. Recently, I made a project where I used python and raspberry pi and had to train some small models on a KITTI data set. I used AI to write the broad structure of the code, but in the end, it took me a lot of time going through python documentation as well as the documentation of the specific tools/modules I used to actually get the code working. Would an experienced programmer get the same work done in an afternoon? Probably. But the code AI output still had a lot of flaws. Someone who knows more than me would probably input better prompts and better follow up requirements and probably get a better structure from the AI, but I doubt they’ll get a complete code. In the end, even to use AI, you have to know what you’re doing to use AI efficiently and you still have to polish the code into something that actually works.
From my experience, AI just seems to be a lesson in overfitment. You can’t use it to do things nobody has done before. Furthermore, you only really get good responses from prompts related to Javascript
I’d be inclined to try using it if it was smart enough to write my unit tests properly, but it’s great at double inserting the same mock and have 0 working unit tests.
I might try using it to generate some javadoc though… then when my org inevitably starts polling how much ai I use I won’t be in the gutter lol
I personally think unit tests are the worst application of AI. Tests are there to ensure the code is correct, so ideally the dev would write the tests to verify that the AI-generated code is correct.
I personally don’t use AI to write code, since writing code is the easiest and quickest part of my job. I instead use it to generate examples of using a new library, give me comparisons of different options, etc, and then I write the code after that. Basically, I use it as a replacement for a search engine/blog posts.
To preface I don’t actually use ai for anything at my job, which might be a bad metric but my workflow is 10x slower if i even try using ai
That said, I want AI to be able to do unit tests in the sense that I can write some starting ones, then it be able to infer what branches aren’t covered and help me fill the rest.
Obviously it’s not smart enough, and honestly I highly doubt it will ever be because that’s the nature of llm, but my peeve with unit test is that testing branches usually entail just copying the exact same test but changing one field to be an invalid value, or a dependency to throw. It’s not hard, just tedious. Branching coverage is already enforced, so you should know when you forgot to test a case.
Edit: my vision would be an interactive version rather than my company’s current, where it just generates whatever it wants instantly. I’d want something to prompt me saying this branch is not covered, and then tell me how it will try to cover it. It eliminates the tedious work but still lets the dev know what they’re doing.
I also think you should treat ai code as a pull request and actually review what it writes. My coworkers that do use it don’t really proofread, so it ends up having some bad practices and code smells.
testing branches usually entail just copying the exact same test but changing one field to be an invalid value, or a dependency to throw
That’s what parameterization is for. In unit tests, most dependencies should be mocked, so expecting a dependency to throw shouldn’t really be a thing much of the time.
I’d want something to prompt me saying this branch is not covered, and then tell me how it will try to cover it
You can get the first half with coverage tools. The second half should be fairly straightforward, assuming you wrote the code. If a branch is hard to hit (i.e. it happens if an OS or library function fails), either mock that part or don’t bother with the test. I ask my team to hit 70-80% code coverage because that last 20-30% tends to be extreme corner cases that are hard to hit.
My coworkers that do use it don’t really proofread, so it ends up having some bad practices and code smells.
And this is the problem. Reviewers only know so much about the overall context and often do a surface level review unless you’re touching something super important.
We can make conventions all we want, but people will be lazy and submit crap, especially when deadlines are close. >
The issue with my org is the push to be ci/cd means 90% line and branch coverage, which ends up being you spend just as much time writing tests as actually developing the feature, which already is on an accelerated schedule because my org has made promises that end up becoming ridiculous deadlines, like a 2 month project becoming a 1 month deadline
Mocking is easy, almost everything in my team’s codebase is designed to be mockable. The only stuff I can think of that isn’t mocked are usually just clocks, which you could mock but I actually like using fixed clocks for unit testing most of the time. But mocking is also tedious. Lots of mocks end up being:
- Change the test constant expected. Which usually ends up being almost the same input just with one changed field.
- Change the response answer from the mock
- Given the response, expect the result to be x or some exception y
Chances are, if you wrote it you should already know what branches are there. It’s just translating that to actual unit tests that’s a pain. Branching logic should be easy to read as well. If I read a nested if statement chances are there’s something that can be redesigned better.
I also think that 90% of actual testing should be done through integ tests. Unit tests to me helps to validate what you expect to happen, but expectations don’t necessarily equate to real dependencies and inputs. But that’s a preference, mostly because our design philosophy revolves around dependency injection.
I also think that 90% of actual testing should be done through integ tests
I think both are essential, and they test different things. Unit tests verify that individual pieces do what you expect, whereas integration tests verify that those pieces are connected properly. Unit tests should be written by the devs and help them prove their solution works as intended, and integration tests should be written by QA to prove that user flows work as expected.
Integration test coverage should be measured in terms of features/capabilities, whereas unit tests are measured in terms of branches and lines. My target is 90% for features/capabilities (mostly miss the admin bits that end customers don’t use), and 70-80% for branches and lines (skip unlikely errors, simple data passing code like controllers, etc). Getting the last bit of testing for each is nice, but incredibly difficult and low value.
Lots of mocks end up being
I use Python, which allows runtime mocking of existing objects, so most of our mocks are like this:
@patch.object(Object, "method", return_value=value)Most tests have one or two lines of this above the test function. It’s pretty simple and not very repetitive at all. If we need more complex mocks, that’s usually a sign we need to refactor the code.
dependency injection
I absolutely hate dependency injection, most of the time. 99% of the time, there are only two implementations of a dependency, the standard one and a mock.
If there’s a way to patch things at runtime (e.g. Python’s unittest.mock lib), dependency injection becomes a massive waste of time with all the boilerplate.
If there isn’t a way to patch things at runtime, I prefer a more functional approach that works off interfaces where dependencies are merely passed as needed as data. That way you avoid the boilerplate and still get the benefits of DI.
That said, dependency injection has its place if a dependency has several implementations. I find that’s pretty rare, but maybe its more common in your domain.
A software tester walks into a bar, he orders a beer.
He orders -1 beers.
He orders 0 beers.
He orders 843909245824 beers.
He orders duck beers.
AI can be trained to do that, but if you are in a not-well-trodden space, you’ll want to be defining your own edge cases in addition to whatever AI comes up with.
Ideally, there are requirements before anything, and some TDD types argue that the tests should come before the code as well.
Ideally, the customer is well represented during requirements development - ideally, not by the code developer.
Ideally, the code developer is not the same person that develops the unit tests.
Ideally, someone other than the test developer reviews the tests to assure that the tests do in-fact provide requirements coverage.
Ideally, the modules that come together to make the system function have similarly tight requirements and unit-tests and reviews, and the whole thing runs CI/CD to notify developers of any regressions/bugs within minutes of code check in.
In reality, some portion of that process (often, most of it) is short-cut for one or many reasons. Replacing the missing bits with AI is better than not having them at all.
Ideally, the code developer is not the same person that develops the unit tests.
Why? The developer is exactly the person I want writing the tests.
There should also be integration tests written by a separate QA, but unit tests should 100% be the responsibility of the dev making the change.
Replacing the missing bits with AI is better than not having them at all.
I disagree. A bad test is worse than no test, because it gives you a false sense of security. I can identify missing tests with coverage reports, I can’t easily identify bad tests. If I’m working in a codebase with poor coverage, I’ll be extra careful to check for any downstream impacts of my change because I know the test suite won’t help me. If I’m working in a codebase with poor tests but high coverage, I may assume a test pass indicates that I didn’t break anything else.
If a company is going to rely heavily on AI for codegen, I’d expect tests to be manually written and have very high test coverage.
Saved this comment. No notes.
The reason tests are a good candidate is that there is a lot of boilerplate and no complicated business logic. It can be quite a time saver. You probably know some untested code in some project - you could get an llm to write some tests that would at least poke some key code paths, which is better than nothing. If the tests are wrong, it’s barely worse than having no tests.
better than nothing
I disagree. I’d much rather have a lower coverage with high quality tests than high coverage with dubious tests.
If your tests are repetitive, you’re probably writing your tests wrong, or at least focusing on the wrong logic to test. Unit tests should prove the correctness of business logic and calculations. If there’s no significant business logic, there’s little priority for writing a test.
The actual risk of those tests being wrong is low because you’re checking them.
If your tests aren’t repetitive they’ve got no setup or mocking in so they don’t test very much.
If your test code is repetitive, you’re not following DRY sufficiently, or the code under test is overly complicated. We’ll generally have a single mock or setup code for several tests, some of which are parameterized. For example, in Python:
@parameterized.expand([ (key, value, Expected Exception,), (other_key, other_value, OtherExpectedException,), ]) def test_exceptions(self, key, value, exception_class): obj = setup() setattr(obj, key, value) with self.assertRaises(exception_class): func_to_test(obj)Mocks are similarly simple:
@unittest.mock.patch.object(Class, "method", return_value=...) dynamic_mock = MagicMock(Class) dynamic_mock...How this looks will vary in practice, but the idea is to design code such that usage is simple. If you’re writing complex mocks frequently, there’s probably room for a refactor.
I know how to use parametrised tests, but thanks.
Tests are still much more repetitive than application code. If you’re testing a wrapper around some API, each test may need you to mock a different underlying API call. (Mocking all of them at once would hide things). Each mock is different, so you can’t just extract it somewhere; but it is still repetitive.
If you need three tests each of which require a (real or mock) user, a certain directory structure to be present somewhere, input data to be got from somewhere, that’s three things that, even if you streamline them, need to be done in each test. I have been involved in a project where we originally followed the principle of, “if you need a user object in more than one test, put it in
setUpor in a shared fixture” and the result is rapid unwieldy shared setup between tests - and if ever you should want to change one of those tests, you’d better hope you only need to add to it, not to change what’s already there, otherwise you break all the other tests.For this reason, zealous application of DRY is not a good idea with tests, and so they are a bit repetitive. That is an acceptable trade-off, but also a place where an LLM can save you some time.
If you’re writing complex mocks frequently, there’s probably room for a refactor.
Ah, the end of all coding discussions, “if this is a problem for you, your code sucks.” I mean, you’re not wrong, because all code sucks.
LLMs are like the junior dev. You have to review their output because they might have screwed up in some stupid way, but that doesn’t mean they’re not worth having.
zealous application of DRY is not a good idea with tests
I absolutely agree. My point is that if you need complex setup, there’s a good chance you can reuse it and replace only the data that’s relevant for your test instead of constructing it every time.
But yes, there’s a limit here. We currently have a veritable mess because we populate the database with fixture data so we have enough data to not need setup logic for each test. Changing that fixture data causes a dozen tests to fail across suites. Since I started at this org, I’ve been pushing against that and introduced the repository pattern so we can easily mock db calls.
IMO, reused logic/structures should be limited to one test suite. But even then, rules are meant to be broken, just make sure you justify it.
also a place where an LLM can save you some time.
I’m still not convinced that’s the case though. A typical mock takes a minute or two to write, most of the time is spent thinking about which cases to hit or refactoring code to make testing easier. Working with the LLM takes at least that long, esp if you count reviewing the generated code and whatnot.
LLMs are like the junior dev
Right, and I don’t want a junior dev writing my tests. Junior devs are there to be trained with the expectation that they’ll learn from mistakes. LLMs don’t learn, they’re perennially junior.
That’s why I don’t use them for code gen and instead use them for research. Writing code is the easy part of my job, knowing what to write is what takes time, so I outsource as much of the latter as I can.
What model are you using? I’ve had such a radically different experience but I’ve only bothered with the latest models. The old ones weren’t even worth trying with
I’ll have to check, we have a few models hosted at our company and I forget the exact versions and whatnot. They’re relatively recent, but not the highest end since we need to host them locally.
But the issue here isn’t directly related to which model it is, but to the way LLMs work. They cannot reason, they can only give believable output. If the goal is code coverage, it’ll get coverage, but not necessarily be well designed.
If both the logic and the tests are automated, humans will be lazy and miss stuff. If only the logic is generated, humans can treat the code as a black box and write good tests that way. Humans will be lazy with whatever is automated, so if I have to pick one to be hand written, it’ll be the code that ensures the logic is correct.
We’re mandated to use it at my work. For unit tests it can really go wild and it’ll write thousands of lines of tests to cover a single file/class for instance whereas a developer would probably only write a fourth as much. You have to be specific to get any decent output from them like “write a test for this function and use inputs x and y and the expected output is z”
Personally I like writing tests too and I think through what test cases I need based on what the code is supposed to do. Maybe if there are annoying mocks that I need to create I’ll let the AI do that part or something.
Generating tests like that would take longer than writing the tests myself…
Nobody is going to thoroughly review thousands of lines of test code.
I’ve seen it generate working unit tests plenty. In the sense that they pass.
…they do not actually test the functionality. Of course that function returns what you’re asserting - you overwrote its actual output and checked against that!
One of the guys at my old job submitted a PR with tests that basically just mocked everything, tested nothing. Like,
with patch("something.whatever", return_value=True): assert whatever(0) is True assert whatever(1) is TrueExcept for a few dozen lines, with names that made it look like they were doing useful.
He used AI to generate them, of course. Pretty useless.
We have had guys submit tests like that, long before AI was a thing.
At least in those situations, the person writing the tests knows they’re not testing anything…
True, I do feel mocked by this code.








